tg-me.com/pro_python_code/1731
Last Update:
Исследовательская группа под патронажем Centrale Supélec (Университет Париж-Сакле) выпустила в открытый доступ EuroBERT — семейство мультиязычных энкодеров, обученных на 5 трлн. токенов из 15 языков, включая русский.
EuroBERT сочетает инновационную архитектуру с поддержкой контекста до 8192 токенов, что делает это семейство идеальным для анализа документов, поиска информации, классификации, регрессии последовательности, оценки качества, оценки резюме и задач, связанных с программированием, решением математических задачи.
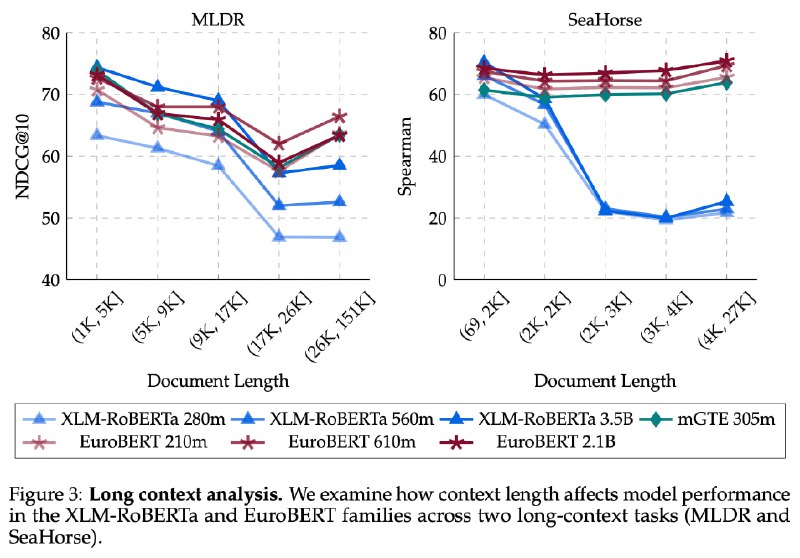
В отличие от предшественников (XLM-RoBERTa и mGTE), EuroBERT объединил GQA, RoPE и среднеквадратичную нормализацию, чтобы достичь беспрецедентной эффективности производительности даже в сложных задачах. Второе немаловажное преимущество EuroBERT - в обучение помимо текстовых данных были включены примеры кода и решения математических задач.
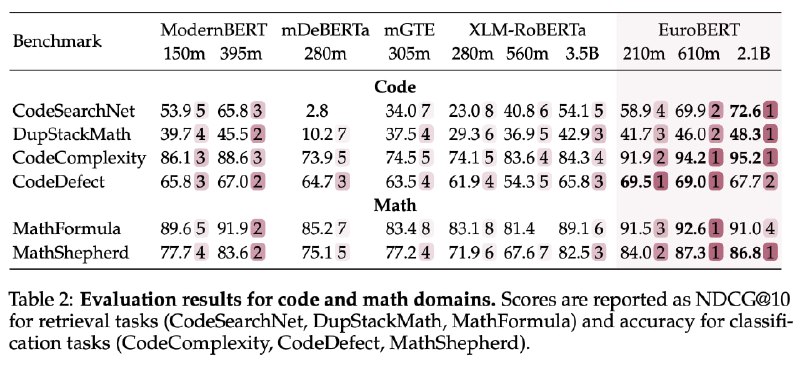
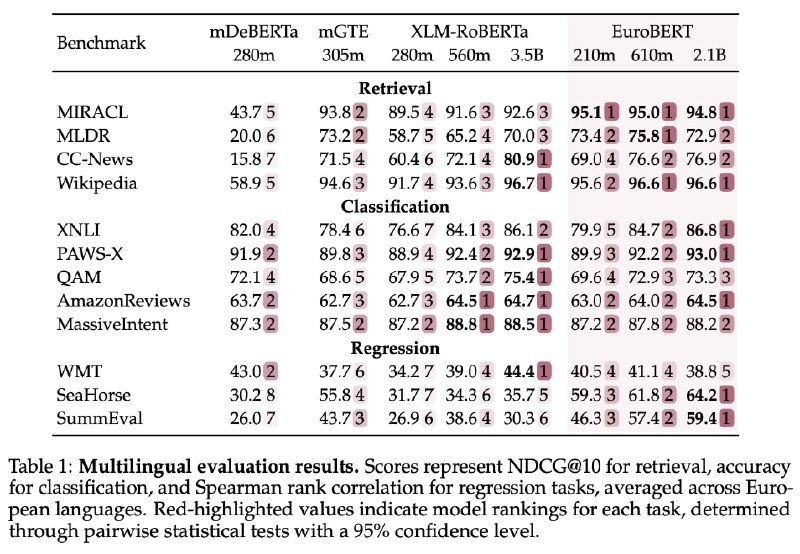
Самая младшая модель EuroBERT с 210 млн. параметров показала рекордные результаты: в тесте MIRACL по многоязычному поиску её точность достигла 95%, а в классификации отзывов (AmazonReviews) — 64,5%. Особенно выделяется умение работать с кодом и математикой — в бенчмарках CodeSearchNet и MathShepherd EuroBERT опережает аналоги на 10–15%.
⚠️ EuroBERT можно использовать непосредственно с transformers, начиная с версии 4.48.0
⚠️ Для достижения максимальной эффективности, разработчики рекомендуют запускать EuroBERT с Flash Attention 2
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_id = "EuroBERT/EuroBERT-210m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id, trust_remote_code=True)
text = "The capital of France is <|mask|>."
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
# To get predictions for the mask:
masked_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)
predicted_token_id = outputs.logits[0, masked_index].argmax(axis=-1)
predicted_token = tokenizer.decode(predicted_token_id)
print("Predicted token:", predicted_token)
# Predicted token: Paris
@ai_machinelearning_big_data
#AI #ML #Encoder #EuroBERT